
 计算机基础
计算机基础 工具集
工具集 技术随笔
技术随笔 个人杂谈
个人杂谈 经验感悟
经验感悟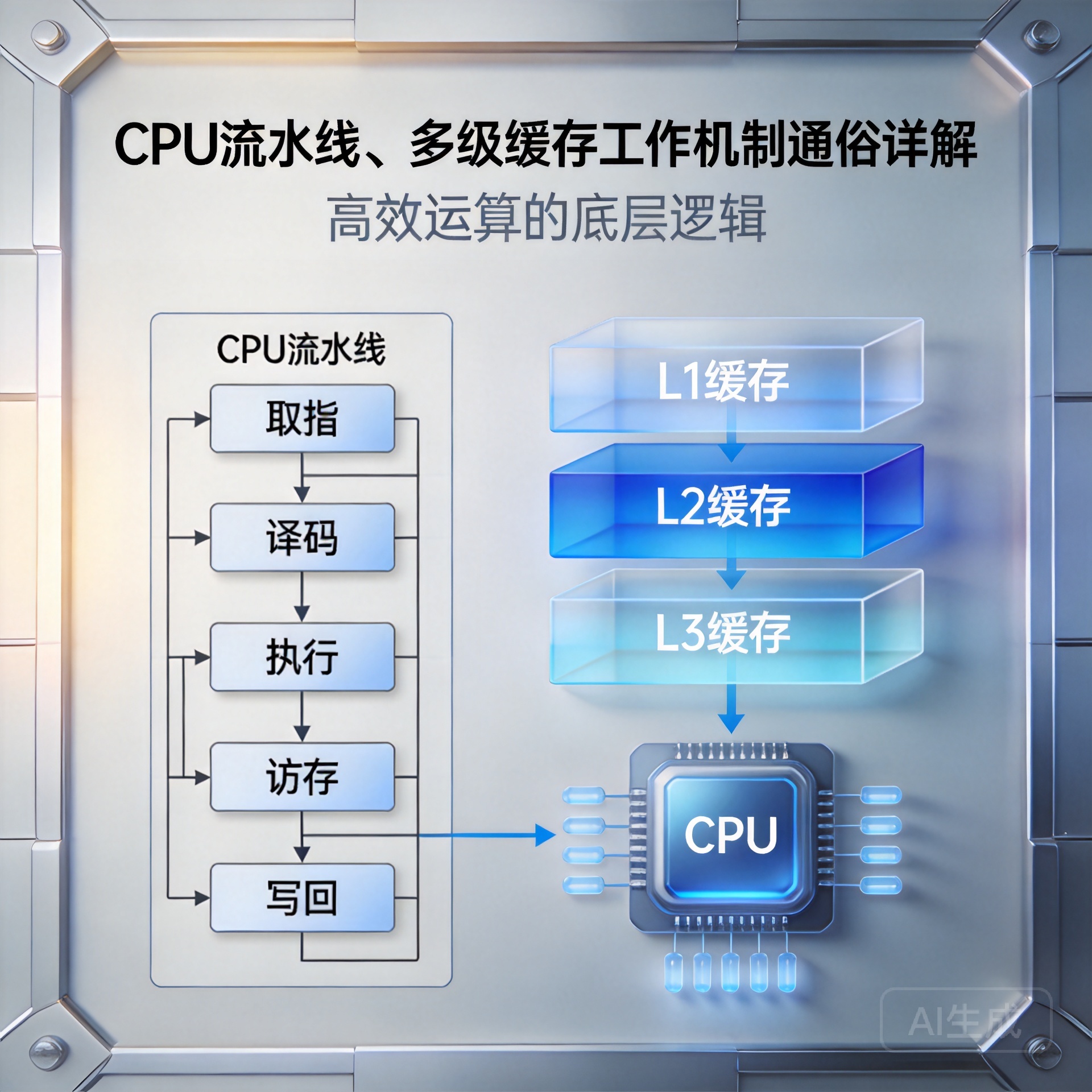
在现代计算机体系结构中,CPU 的运算速度早已将主内存远远甩在身后。为了不让超快的处理器因等待数据而“空转”,工程师设计了两大核心机制:CPU 流水线与多级缓存。理解它们的工作原理,是掌握硬件性能与编写高效代码的基石。
一、CPU流水线:把“串行等待”变成“并行流水”
传统的指令执行遵循严格的先后顺序:取指、译码、执行、访存、写回。如果必须等一条指令完全走完,下一条才能开始,效率极低。流水线技术将这一过程拆分为多个独立阶段,就像汽车装配线:当第一条指令进入“执行”环节时,第二条可以同步进行“译码”,第三条正在“取指”。各阶段由专用电路并行处理,单位时间内完成的指令数量大幅提升。不过,流水线最怕遇到“分支跳转”(如 if-else 判断),一旦猜错方向,流水线就必须清空重来。为此,现代 CPU 引入了分支预测器,提前预判代码走向,最大限度减少流水线停顿。
二、多级缓存:在“速度”与“容量”间寻找平衡
CPU 再快,若每次读写数据都要去访问较慢的内存,性能也会大打折扣。多级缓存(L1、L2、L3)正是为此而生。L1 缓存紧贴计算核心,速度最快但容量最小,专门存放当前线程最频繁使用的数据与指令;L2 容量稍大,作为 L1 的后备;L3 通常被多个核心共享,容量最大但延迟略高。这套设计完美契合了“程序局部性原理”:CPU 访问过的数据,大概率很快会再次访问。当数据命中缓存时,流水线即可满血运行;若未命中(Cache Miss),则需向下一级或内存读取,此时流水线会产生“气泡”等待。
三、协同工作与性能启示
流水线负责“不停工”,缓存负责“供好料”,两者相辅相成。高缓存命中率是维持流水线高效吞吐的前提。在实际开发中,理解这一机制能直接指导性能优化:例如避免频繁的随机内存访问、保持数据结构连续以提升缓存行利用率、合理控制循环嵌套层级等。只有顺应底层硬件的调度逻辑,才能让代码真正释放 CPU 的极限性能。